Save as PDF
Opens your browser print dialog — select "Save as PDF" to download.
AL-702 (B) (GS)
B. Tech., VII Semester
Examination, December 2025
Grading System (GS)
Advanced Machine Learning
Note: (i) Attempt any five questions.
किसी पांच प्रश्नों को हल कीजिए।
(ii) All questions carry equal marks.
सभी प्रश्नों के समान अंक हैं।
(iii) In case of any doubt or dispute the English version question should be treated as final.
किसी भी प्रकार के संदेह अथवा विवाद की स्थिति में अंग्रेजी भाषा के प्रश्न को अंतिम माना जायेगा।
Define Artificial Neural Networks. What is the role of the cost function in training Artificial Neural Networks?
कृत्रिम तंत्रिका नेटवर्क को परिभाषित कीजिए। कृत्रिम तंत्रिका नेटवर्क के प्रशिक्षण में लागत फलन की क्या भूमिका है?
Describe the role of gradient descent in the backpropagation process. How does it influence weight updates?
बैकप्रोपैगेशन प्रक्रिया में ग्रेडिएंट डिसेंट की भूमिका का वर्णन कीजिए। यह वेट अपडेट को कैसे प्रभावित करता है?
Describe the architecture and learning process of a multi-layer perceptron.
बहु-परत परसेप्ट्रॉन की वास्तुकला और सीखने की प्रक्रिया का वर्णन करें।
What is recursive induction in decision trees? Explain.
निर��णय ट्री में पुनरावर्ती प्रेरण क्या है? व्याख्या करें।
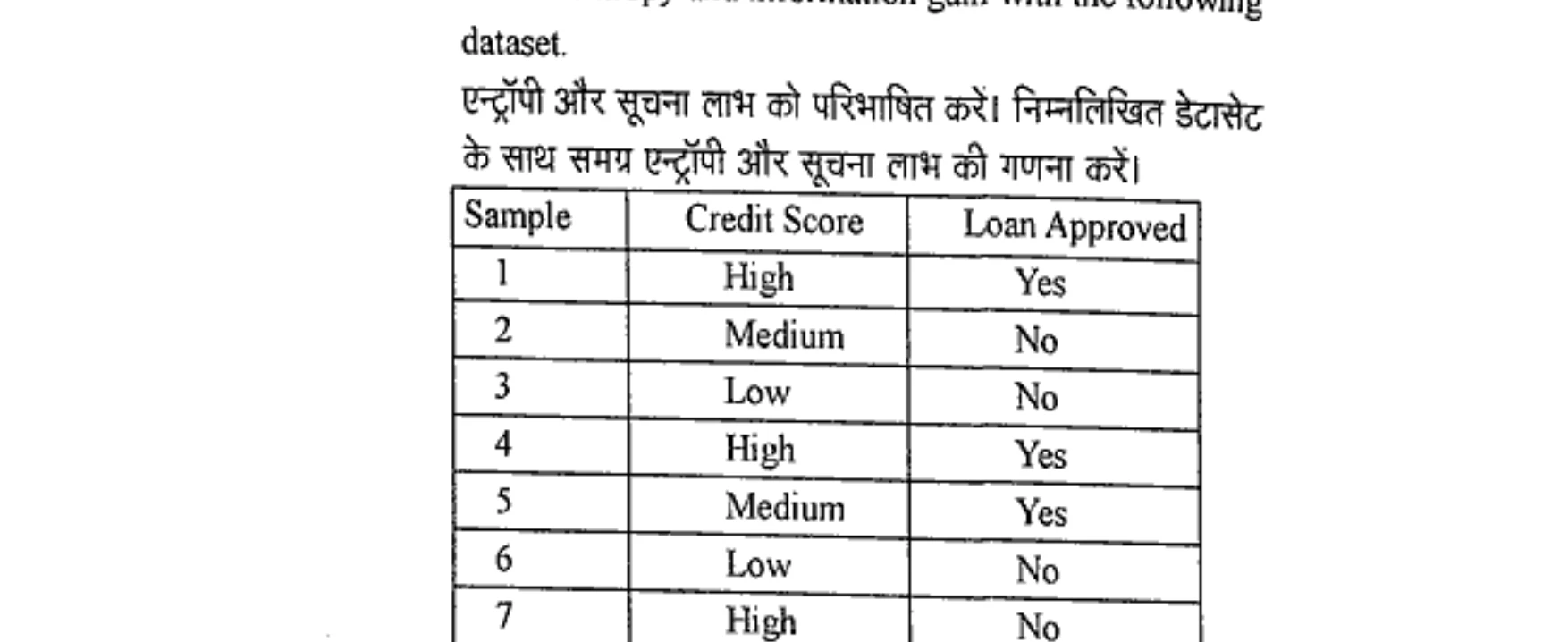
Define entropy and information gain. Calculate the overall entropy and information gain with the following dataset.
एन्ट्रॉपी और सूचना लाभ को परिभाषित करें। निम्नलिखित डेटासेट के साथ समग्र एन्ट्रॉपी और सूचना लाभ की गणना करें।
How does noisy data affect decision tree performance? Write the strategies to overcome them.
शोरगुल डेटा निर्णय ट्री के प्रदर्शन को कैसे प्रभावित करता है? इनसे निपटने की रणनीतियाँ लिखें।
Compare Bagging and Boosting techniques in ensemble learning.
समूह शिक्षण में बैगिंग और बूस्टिंग तक���ीकों की तुलना करें।
Describe the working mechanism of a Random Forest algorithm.
रैंडम फॉरेस्ट एल्गोरिथम की कार्य प्रणाली का वर्णन करें।
Why ensemble methods offer greater robustness compared to individual models? Discuss.
ब्लल मॉडल की तुलना में समूह विधियाँ अधिक सुदृढ़ता क्यों प्रदान करती है? चर्चा कीजिए।
Explain the Bellman Equations in the context of Reinforcement Learning.
सुदृढीकरण अधिगम के संदर्भ में बेलमैन समीकरणों की व्याख्या कीजिए।
Differentiate between Q-learning and SARSA algorithms.
क्यू-लर्निंग और सार���ा एल्गोरिदम के बीच अंतर स्पष्ट कीजिए।
Describe the concept of Policy Gradient methods in Reinforcement Learning.
सुदृढीकरण अधिगम में नीति प्रवणता विधियों की अवधारणा का वर्णन कीजिए।
What is temporal difference learning and how does it differ from Monte Carlo methods?
टेंपोर��� डिफरेंस लर्निंग क्या है और यह मोंटे कार्लो विधियों से कैसे भिन्न है?
How does Generative Adversarial Imitation learning differ from standard RL approaches?
जनरेटिव एडवर्सरियल इमिटेशन लर्निंग मानक आरएल दृष्टिकोणों से कैसे भिन्न है?
Write short note on any two :
किन्हीं दो पर संक्षिप्त टिप्पणी लिखिए:
Value iteration and Policy Iteration
मूल्य पुनरावृत्ति और नीति पुनरावृत्ति
Recent Trends in RL Architectures
RL आर्किटेक्चर में हालिया रुझान
Random Forest
यादृच्छिक वन
Least Squares Methods
न्यूनतम वर्ग विधियाँ